Git isn’t the easiest of software, so many people treat it as a necessary evil and use it as the bare minimum they can get away with. But if you treat it right (and practice a little), git can be your friend.
In the last couple of years I’ve taught git to students and coached colleagues on git. I got exposed to several different workflows on a variety of git forges and was involved in hammering out the workflow for a couple of projects. I was also fortunate enough to work with some people who know almost everything about git. Naturally, all these also involved a lot of discussions and thinking about git, which made me realize, that a little bit of effort can go a long way, when dealing with commits.
Below you will find the synthesis of these discussions and experiences: a set of rules, their rationale and a short practical guide to creating useful commits.
The rules
The reasons behind these rules are a combination of a) fully exploiting git tooling, b) a courtesy to your future self, current and future colleagues, and c) consistency. Of course they only apply to the final, finished commits, but more on this later.
- The commit title should be short, ideally around 50 characters, but definitely less than 72.
- Use a short prefix in the commit title that places the commit’s scope within the wider project (e.g.:
ci:,ui:,train:,doc:). - The commit body should be wrapped at 72 chars.
- The commit body should explain why the commit is needed, in as much detail as necessary (picture writing it for a non-senior, recently onboarded colleague with no detailed knowledge about the code).
- The commit body should make use of relevant commit-trailers.
- Each commit should be self-contained, changing one well-scoped part of the code (called an atomic commit).
- Each commit should produce working code, even if you are working on a chain of them.
- The commit (title and body) should be written in imperative, as if you were instructing git on what to do (“Fix bug” instead of “Fixed bug”).
- You should usually avoid using merge commits. Instead, you should always rebase first and then fast-forward or apply patches.
Rationales
Make git log readable
On my laptop, a split screen terminal is around 90 characters wide. Running
git log --oneline will prefix the title with 8 extra characters (7 characters
of hash and a space) and if the first commit is actually in sync with the
origin it’ll take 53 characters. If you want to add the date and the commit
author as well to the line, that’s even less space. Thus it makes sense to make
your title short and the body hard wrapped.

This is of course not just about your command line. Since short titles and hard wrapped commit bodies have pretty much always been the norm, most git forges (github, gitlab, bitbucket etc.) will also wrap commit titles after 72 characters, making longer commit titles particularly unreadable online.
Make git blame useful and code review easier
Git blame shows which commit modified each line of a file last. It can be
incredibly useful when you’re staring at a piece of code and you have no idea
why it was written like that. You check the commit with git blame and realize
that oh, that strange condition was added two years ago to work around a legacy
system that is not around anymore.
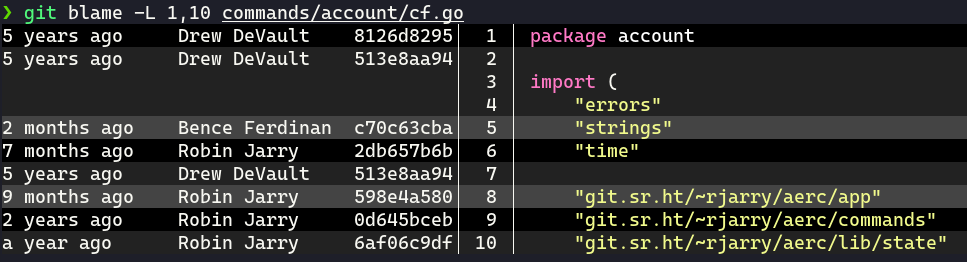
Obviously, this only works if the commit actually explains why the commit was
added (I really like
this story about a good
commit message). Moreover, if this workaroud was added in a well scoped commit (instead
of five successive commits with only the last one actually getting it to work),
then dropping the extra complexity of the now redundant workaround is trivial
with git revert.
Having commits that are explained in detail and are well scoped also help out with reviewing them, compared to trying to make sense of several unrelated changes without any explanation.
Make git bisect work
You are in a situation where somewhere along the line during development a bug
was introduced into an already implemented feature and you are not sure where.
Using git bisect you can mark the
current commit as “bad”, mark a commit in the history where the feature was
still working as “good”, and git will help you quickly narrow down the commit
that introduced the bug. It will walk you through a binary search of the
history between the “good” and the “bad” commit, to find the first commit after
the known “good” one where the feature was broken. You either test each offered
commit manually, or you can automate the process with a script.
Bisecting is incredibly useful, and can save a lot of time when hunting bugs, but only if the commit history is in good shape (for tutorials, see here). Bisecting when there are commits where the code is just plain not working is hard and easy to get wrong, because you can’t test your specific feature if the entire software is broken. Automated bisecting is probably out of the question.
Of course, if bisect is successful, but the commit at fault is not well scoped and lacks explanation about the changes you still might be in trouble. Figuring out how to fix the bug will be harder and reverting the commit is likely off the table.
On avoiding merge commits
First, avoiding merge commits has a readability aspect to it. In the most extreme case of having a merge commit after every proper commit the merge commits carry zero information, but take half the screen real-estate. This is true for less extreme cases as well: as long as the proper commits are well crafted the merge commits will carry little to no information even after long stretches of commits.
Second, merge commits make keeping two branches in sync irritating. Any time commits from a source branch are merged with a merge commit to a target branch, the source branch will need to retrieve the merge commit to keep in sync.
I’d argue that merge commits only make sense for very long lived branches with a large number of commits. For example branches being worked on for several months with 50+ commits, but please don’t quote me on the exact numbers.
If you still want to have merge commits for some reason at least rebase before merging.
Miscellaneous
We’ve already touched on well scoped commits making git revert much more
useful. This is of course also true for git cherry-pick. If you are in
a situation where you need to maintain slightly different versions of your
program in parallel git cherry-pick is a great tool, but only if commits really
make sense on their own.
The usage of commit trailers (when relevant) is just good practice, since git
has tooling around them (see git interpret-trailers). The
most common ones are widely used in automation or understood as having
a specific meaning. The most famous trailer is probably
Signed-off-by:,
you’ve likely also seen e.g. Fixes: for automatically closing issues, but
things like Co-authored-by: for acknowledging help or Link: for adding
external links can also be useful.
The last thing I haven’t touched upon is why write commits in imperative mood?
Well, this is mostly just aesthetics and the core of the rule is actually to
write commits consistently with the rest of the project. That said, most
projects do not have rules for this, but when they have, I have only yet seen
ones where imperative was required. Git itself also uses imperative in
automatic commits (e.g. git revert creates titles like revert "bad commit"). Finally, to me it feels more natural to read imperative during
a review, then say past tense (the proposed change has clearly not yet been
applied, right?). I always picture instructing git on what to do with the
codebase when the commit is being applied.
Comments on external constraints
Working with pull/merge request based forges
Most Git forges have workflows based on pull/merge requests (think e.g. Github, Gitlab, Bitbucket). The conceptual problem I have with these is that their main focus is on handling differences between branches instead of individual commits. Their default views treat all the commits as one big blob of changes making it hard to review commit by commit. It’s usually not even possible to directly comment on the commit messages themselves, only on the code changes (i.e. most of them support commenting on a specific line of code, but not the commit title or body). This promotes not paying much attention to an individual commit, but you still can and should.
Another thing these forges incentivize are merge commits. They offer a setting for merge/pull requests called the merge strategy and the default setting is always merging with a merge commit. Fortunately, this can be changed to fast-forwarding. In this case, instead of merging, the commits from the source branch are replayed on top of the target branch, creating a nice linear history (of course for this you first need to make sure the source branch is rebased on top of the target branch). If you really can’t live without merge commits, an alternative option is having a semi-linear history with a rebase-and-merge strategy.
An interesting option for merge strategies is to squash the entire pull/merge request into a single commit, before merging or fast-forwarding. This may actually be a valid strategy, but that means that now this squashed pull/merge request is your commit, thus everything we have talked about above should now apply to this single resultant commit. I think it’s usually more viable to just disable this option and do any necessary squashing manually.
For a more detailed and visual explanation of the merge strategies, see e.g. here.
As a quick side note: If you didn’t even know that pull/merge requests is actually not the only way to collaborate using git, you might find this an interesting read and I highly recommend that you try out the interactive git over email tutorial (also check out aerc, which, in my obviously totally unbiased opinion, is the best email client for git over email). I found that the different perspective of git over email greatly helped my understanding of how git works, so even if you will never use it in practice, it’s worth to do the tutorial at least. Also sometimes it’s just easier to send someone a patch in email rather than to set up a branch for the commit, push that branch somewhere and then email them the link.
Working with conventional commits
The core idea of conventional
commits is to write
commits, so that semantic versioning and changelogs
could be automated. My problem with this is that versioning and changelogs are
user facing documentation, while the git history is a developer facing
documentation. This is like when corporate requires you to create
“predocuments”, those powerpoint presentations that must also serve as
a report/document, making you end up with a wretched abomination that is good
for neither. If you want an automatic changelog I suggest to document changelog entries
within the commit, using git trailers (this is how
aerc handles
this). Of course this is more work, so if you’re going for automatic versioning
and changelogs with the least effort, I won’t blame you for going with
conventional commits, but otherwise, I don’t think it makes much sense. The
breaking change trailer and ! in the title for breaking changes is also
a nice idea.
If you do use conventional commits, you can still stick to most of our rules: just make the optional scope (which is like our prefix) and the optional message body required instead.
In practice
The size (and number) of commits does not matter
You may have noticed, that the rules do not include anything about the size of commits, or the number of commits. Indeed, the requirement that each commit be well scoped and that each commit should lead to working software may lead to situations which you might find surprising at first.
It is entirely possible that a commit is only a single letter change, even if in the next commit, you change the same file. A practical example: you introduce a new feature to your program, that requires adding several new parameters to a configuration file and completely unrelated to this new feature you need realize you need to change an already existing parameter in this configuration file. These changes should be in two separate commits, the first explaining why the feature is being added, the second explaining why the existing parameter must change.
A patch series (pull request) may have multiple commits touching the same line. Again a practical example: your project uses a templating language, which is already used in several places, but you realize that to implement the new feature that you want, you need to change to a more powerful templating language. This should be done in two commits, first switching the entire codebase to the new language without touching the existing features and a second commit to actually add the new feature. Inevitable, both commits will touch the lines where the new feature was actually required.
Staging hunks instead of files
Getting started tutorials will teach you how to stage files with git add. But it is possible to only stage some
changes in a file using git add -p (see
here on how to use this) or even
more granular with git add -e. Although
these commands can be directly used, I find that this is where a good visual
editor integration is the most helpful.
Staging hunks instead of files allows you to split your changes into those well scoped commits.
Actively rewrite history
As long as the branch/repository you are pushing to is not one that is consumed by users (e.g. it is a feature branch and not the dev or master branch) it is absolutely okay to force push. Also, be not afraid! The git reflog will have all your commits for a long time, even if they are currently unreachable from your branch. If you diligently commit, nothing will be lost, even if something goes wrong.
When working on a feature that can be done in a single commit, the best
strategy is to commit early and then constantly edit this commit as you make
changes. To add your changes to the latest commit instead of a new one, you
git add as usual, and then commit with git commit --amend
or git commit --amend --no-edit
if the commit message is fine. This is actually less work than adding a new
commit, if you already have a good commit message and everything is already
tidy.
If you need to split the latest commit you can do the reverse of git add -p with
git reset -p.
Alternatively you can run git reset HEAD^, which will reset git to the
previous commit, but leave your changes in the working directory (git reset --soft HEAD^
is also an option). The ^ means the parent commit, so the one before HEAD,
and HEAD is a reference to the current commit (see
here in detail
how to reference specific commits). If you already had a nice commit message,
then resetting will drop it, but you can still retrieve it by using git commit --reuse-message=ORIG_HEAD,
or using any other way to reference a specific commit instead of
ORIG_HEAD.
If you’d rather just first use a lot of git commit -m "wip"
to save your work for later, you could also git reset origin/master (assuming you branched off
from master) and go about staging hunks into an appropriate number of commits in one go. If
origin/master has actually progressed away from where you branched off from,
then resetting to the first common ancestor can done by running git reset `git merge-base origin/main HEAD` : the expression within the
backtick will evaluate to the first common ancestor between master and your
current branch, i.e. the commit you originally branched off from.
A more complicated situation is when you need to edit commits that are not the
last one. If all hell breaks loose you can always just reset to the root of
your branch like above, but usually there is an easier option with git rebase. If you want to change commit
6b8ed1e0 that is a couple of commits back, you can create a fixup commit by
staging the necessary changes and running git commit --fixup=6b8ed1e0.
This adds a new special commit, so that if you run git rebase --autosquash (usually something like git rebase --autosquash origin/master),
git will know to squash this new commit into 6b8ed1e0. This --fixup has
a couple of variants and there is also --squash, see man
git-commit.
The most versatile option is using git rebase --interactive, e.g. git rebase -i HEAD~4 to manipulate the last four commits.
This allows you to do all of the above, and more, e.g.
edit a specific
commit during rebase.
A nice trick to check if rebasing did what you think is using
range-diff. If you ran rebase with
say HEAD~4, then git range-diff ORIG_HEAD~4..ORIG_HEAD HEAD~4..HEAD (note
the two ranges given) will compare your changes commit-by-commit.
For more details I recommend this excellent tutorial on rebasing.
Some of the above in practice as a not-so-smooth asciinema cast:
Recommended settings
These settings will make life easier (see my git config):
git config --global rebase.autoSquash true # autosquash by default in interactive rebase
git config --global rebase.autoStash true # stash and reapply unsaved changes during rebase
git config --global pull.rebase true # do a rebase when pulling from remote
git config --global rerere.enabled true # remember resolved merged conflicts
See this about rerere in detail. It’s also worth to note that you can create short aliases in git for long commands you use often.
The documentation for most available options is in man git-config or in the specific tool’s man page.
Tooling
Set up your shell so git commands, especially ones that take commit references have good autocomplete, e.g. with fzf search (I use this on zsh).
Set up your editor, so it’s easy to stage hunks, do amends, rebase to specific commits etc. Unfortunately, I can only make recommendations for vim, but I’m quite sure that most editors have at least decent git support. For vim I use fugitive, vim-flog which is basically a fugitive extension for viewing and interacting with the git log, and vim-gitgutter for visually staging hunks (see my config).
I also find lazygit to be useful and is definitely worth to check out.
How seriously should I take this?
That depends. Chances are that even the most serious projects will start
with git commit -m "initial commit". The longer your project is likely to be
around, the more people are likely to interact with it in the future, and the
more collaborators you currently have on the project, the more you should take
it seriously. And of course, not all parts are equally important or applicable
to every particular situation, especially with external constraints like
already existing tooling and conventions in your team/company.
Personally, practising the above has saved me hours of debugging on even smaller projects, so I try to be diligent from the start, but your mileage may vary. At first it will probably be harder than just churning out commits, but with some practice the overhead quickly becomes minimal. Not to mention, that since basically every project and company uses git, it’s a pretty directly transferable skill, unlike that n+1th framework you learnt yesterday.
References
- Tim Pope on commit messages
- linux preferred commit style
- aerc contributing instructions and aerc history as an example
- and of course if you want a deeper understanding, you should read the git pro book
Acknowledgments
Thanks to Koni Marti, Robin Jarry and István Papucsek for reading the first draft.